In this latest version, we develop the Robot TXT Generator tool with export features and useragent features. The export feature will make it easier for you to check the code on Google Rich Result. Meanwhile, the useragent feature will allow you to add more commands to the Robot TXT Generator. This makes it easier for the txt Robot to specifically sort out which content you want to cover and which ones are displayed.
In this latest version, we develop the Robot TXT Generator tool with export features and useragent features. The export feature will make it easier for you to check the code on Google Rich Result. Meanwhile, the useragent feature will allow you to add more commands to the Robot TXT Generator. This makes it easier for the txt Robot to specifically sort out which content you want to cover and which ones are displayed.
What's New
Last update Oct 13, 2023
30 Tools for Countless Solutions! cmlabs has reached a remarkable milestone with the release of 30 cutting-edge tools designed to empower businesses and individuals in the digital realm. All 30 tools, from Test & Checker, Sitemap.XML, and Robots.TXT to various JSON-LD Schema Generator, have been launched to address specific needs and challenges across diverse industries. Together with cmlabs tools, you can stand at the forefront of technological advancements. Try our tools based on your needs now!
Notification centerSEO Services
Get a personalized SEO service and give your business a treat.
Digital Media Buying
Get a personalized SEO service and give your business a treat.
SEO Content Writing
Get a personalized SEO service and give your business a treat.
SEO Political Campaign
Get a personalized SEO service and give your business a treat.
Backlink Services
Get a personalized SEO service and give your business a treat.
Other SEO Tools
Broaden your SEO knowledge
Free on all Chromium-based web browsers


Robots.txt Generator
Robots.txt generator is a tool that is able to make it easier for you to make configurations in the robots.txt file. The robots.txt generator from cmlabs contains all the commands you can use to create a robots.txt file, from specifying a user-agent, entering a sitemap path, specifying access permissions (allow or disallow), to setting crawl-delay.
By using the robots.txt generator, you do not need to manually write the robots.txt file. Just enter the command you want to give the web crawler, then set which pages are allowed or not allowed to be crawled. How to use the robots.txt generator is quite easy, with just a few clicks.
Robots.txt is a file containing certain commands that decide whether the user-agent (web crawler of each search engine) is allowed or not to crawl website elements. The functions of robots.txt for your website are as follows:
Generally, the location of the robots.txt file is in the main directory of the website (e.g domain root or homepage). Before you add it, the robots.txt file is already in the root folder on the file storage server (public_html).
However, you will not find the file when you open public_html. This is because this file is virtual and cannot be modified or accessed from other directories. To change commands in robots.txt, you need to add a new robots.txt file and save it in the public_html folder. In this way, the configuration in the new file will replace the previous file.
The robots.txt syntax can be interpreted as the command you use to notify web crawlers. The robots.txt generator from cmlabs also provides a syntax that the web crawler recognizes. The five terms commonly found in a robots.txt file are as follows:
What is meant by a user-agent in robots.txt is the specific type of web crawler that you give the command to crawl. This web crawler usually varies depending on the search engine used.
Some examples of user agents that are often used are Googlebot, Googlebot-Mobile, Googlebot-Image, Bingbot, Baiduspider, Gigabot, Yandex, and so on.
The command used to tell the user-agent not to crawl the specified URL path. Make sure you have entered the correct path because this command is case-sensitive (eg “/File” and “/file” are considered different paths). You can only use one “Disallow” command for each URL.
This command is used to tell web crawlers that they are allowed to access the path of a page or subfolder even if the parent page of that page or subfolder is disallowed.In practice, the allow and disallow commands are always followed by the “directive: [path]” command to specify the path that may or may not be crawled. Careful attention must be paid to writing the path because this command distinguishes between upper/lower case letters (eg “/File” and “/file” are considered as different paths).
The function of this command in robots.txt is to tell web crawlers that they should wait a while before loading and crawling the page content. This command does not apply to Googlebot, but you can adjust the crawl speed via Google Search Console.
This command is used to call the XML sitemap location associated with a URL. It is also important to pay attention to the writing of the sitemap command because this command distinguishes upper / lower case letters (eg "/Sitemap.xml" and "/sitemap.xml" are considered different paths).
After understanding the commands you can give the web crawler, we will next show an example of the www.example.com website's robots.txt, which is stored in the following www.example.com/robots.txt directory:
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
User-agent: Googlebot
Disallow: /nogooglebot
The first and second lines are commands that tell the default web crawler that they are allowed to crawl URLs. Meanwhile, the third line is used to call the sitemap location associated with that URL.
The fourth and fifth lines are the commands given to Google's web crawler. This command does not allow Googlebot to crawl your website directory (forbids Google from crawling the “/nogooglebot” file path).
Before creating a robots.txt, you need to know the limitations that the following robots.txt file has:s
While Google and other major search engines have complied with the commands in the robots.txt file, some crawlers belonging to other search engines may not comply.
Each search engine has a different web crawler, each crawler may interpret commands in different ways. Although a number of well-known crawlers have followed the syntax written in the robots.txt file, some crawlers may not understand certain commands.
While Google doesn't crawl or index content that robots.txt doesn't allow, Google can still find and index those URLs if they're linked from other websites. Thus, URL addresses and publicly available information can appear in Google search results.
Thus the discussion about the robots.txt generator from cmlabs. Using this tool, you can simplify the workflow of creating robots.txt files. With just a few clicks, you can add configurations to the new robots.txt file.
To create a robots.txt file using this tool, follow these steps:
One way to create a robots.txt file is to visit the robots.txt generator page. On that page, you can set the commands you will give the web crawler.
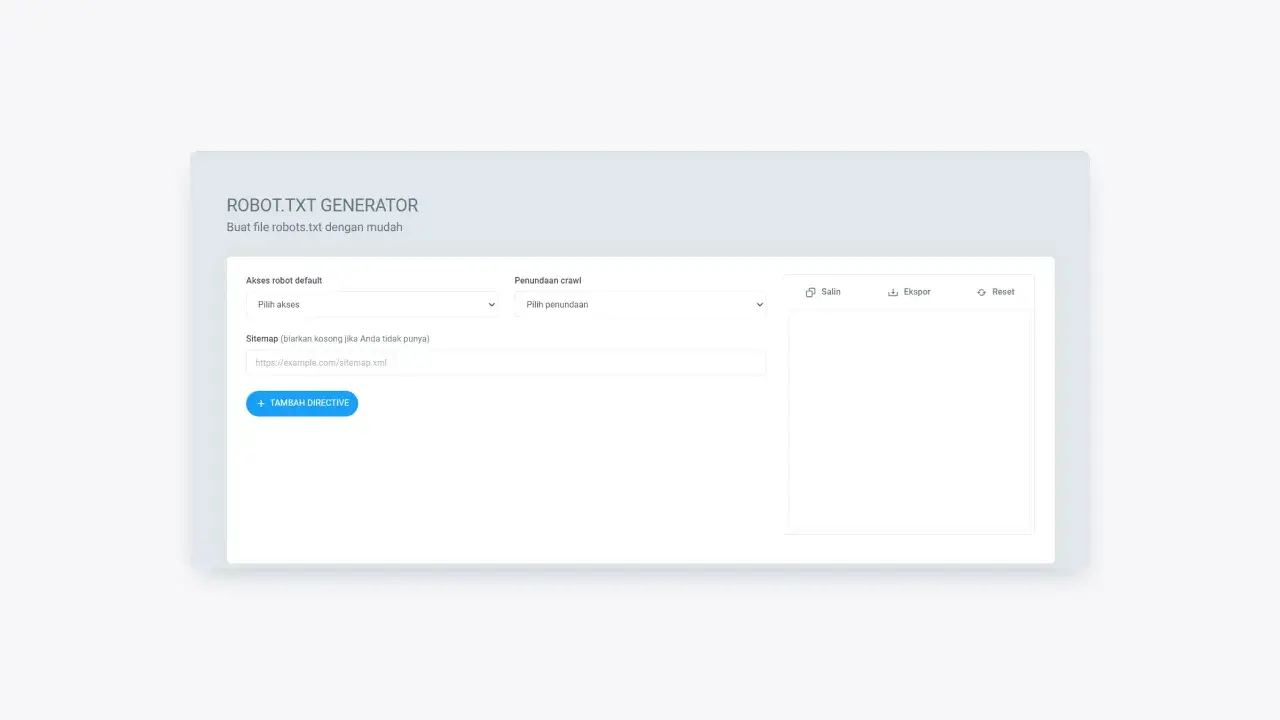
Figure 1: The robots.txt generator page view from cmlabs
Specify access permissions for the default web crawlers, whether they are allowed to crawl URLs or not. There are two options that you can choose, namely, allow and disallow.
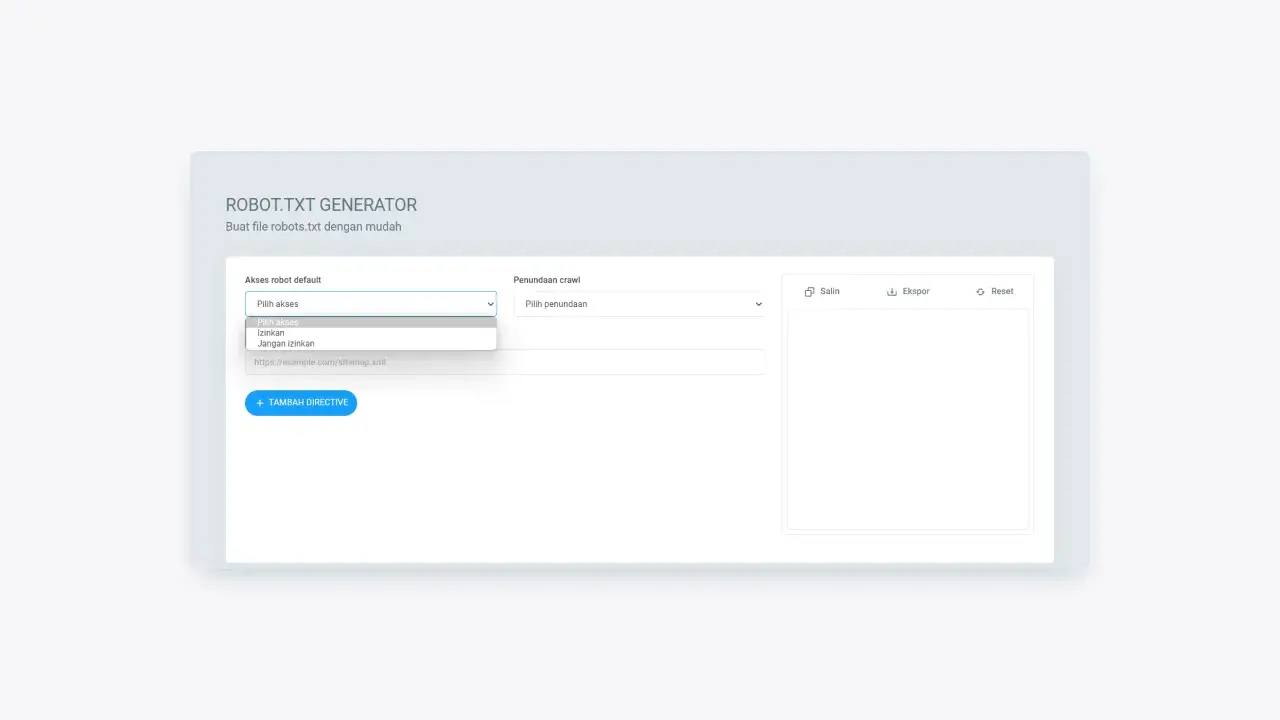
Figure 2: Dropdown view of the permission options granted to the default robot
You can set how long the crawl delay will be for the web crawler. If you set crawl-delay then the web crawler will wait for some time before crawling your URL. Robots.txt generator allows you to choose without crawl delay or delay for 5 to 120 seconds.
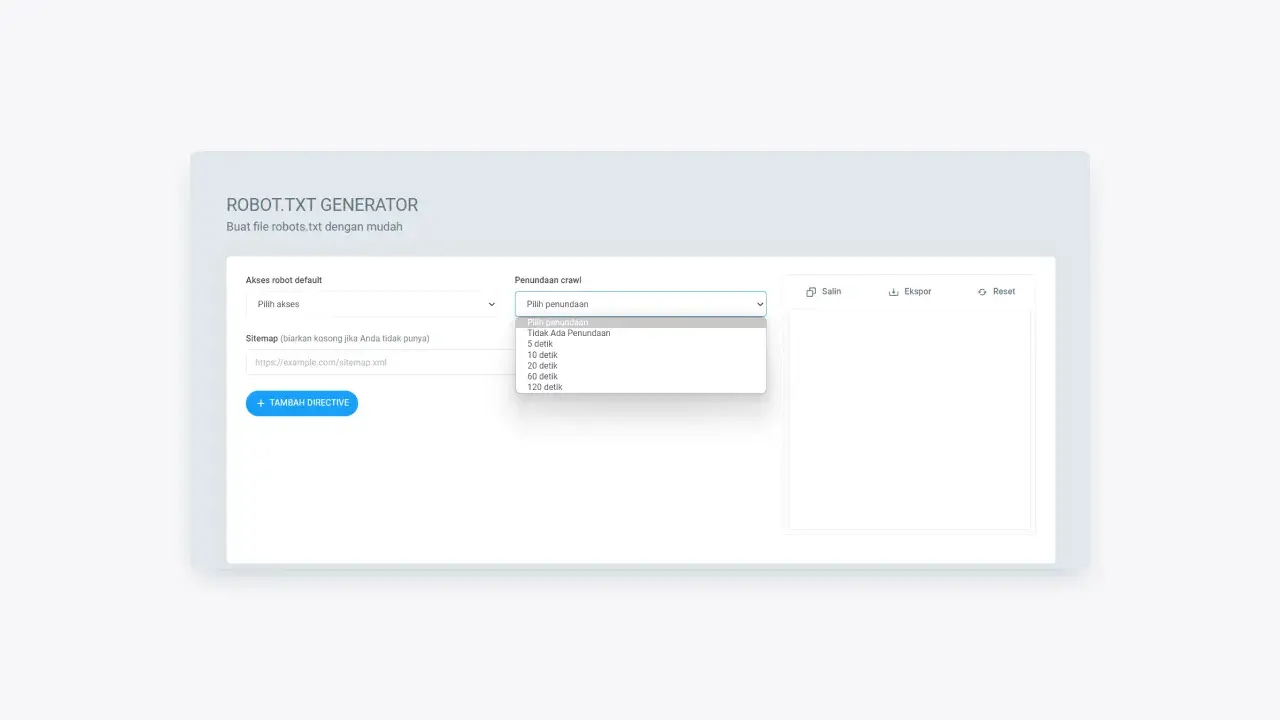
Figure 3: A dropdown view of the crawl delay options provided to the default robot
A sitemap is a file that lists the URLs of your website, with this file, web crawlers will find it easier to crawl and index your site. You can enter the sitemap path into the field provided.
Make sure you have entered the correct sitemap path because this command is case sensitive (eg “/Sitemap.xml” and “/sitemap.xml” are considered different paths).
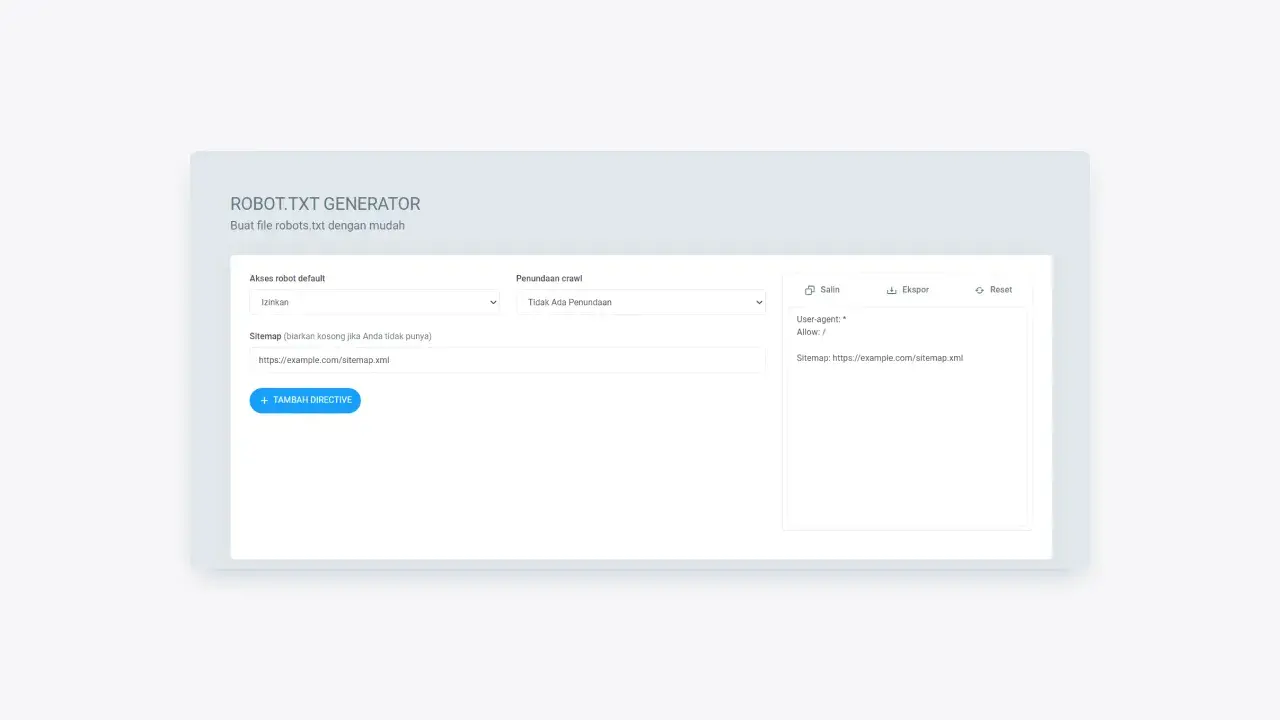
Figure 4: The display field for entering the sitemap path associated with your URL
You can add directives to the robots.txt file by pressing the "Add Directive" button. Directives are commands given to web crawlers to tell you whether you allow or deny them to crawl certain URLs.
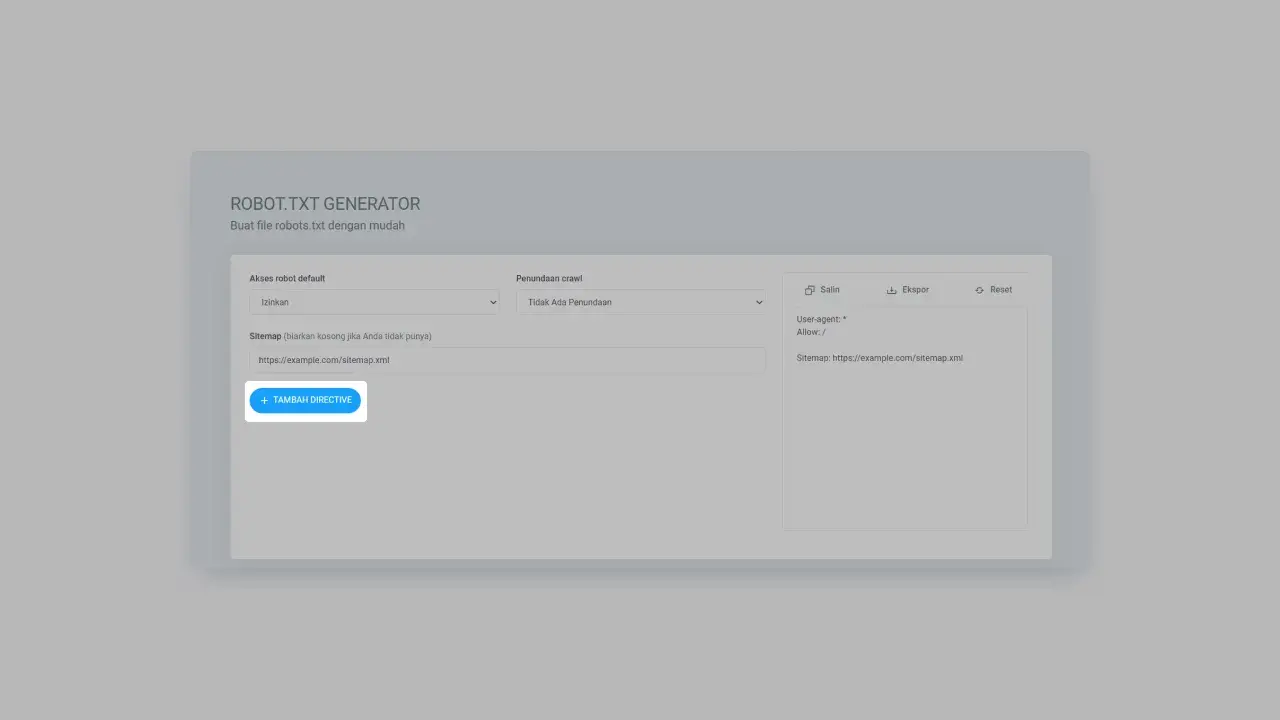
Figure 5: Button for adding commands to be executed by the web crawler
In the robots.txt generator, there are three rules that you need to adjust in the directive section, namely:
You can set the access permissions granted to web crawlers, whether you allow or disallow them from crawling your web pages. The options that can be used allow and disallow.
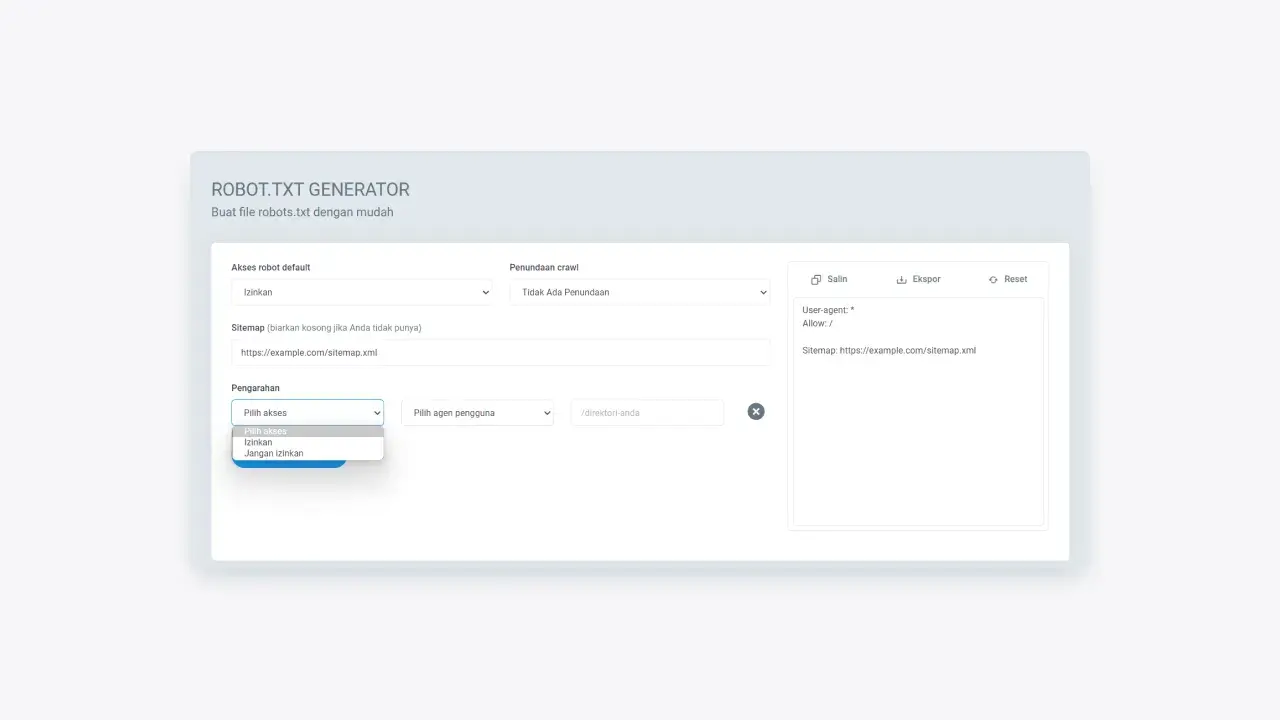
Figure 6: Choice of access permissions to be granted to web crawlers
A user-agent is the type of web crawler that you will instruct to crawl. The choice of this web crawler depends on the search engine used, such as Baiduspider, Bingbot, Googlebot, and others. The web crawler option can be selected via the available user-agent dropdown.
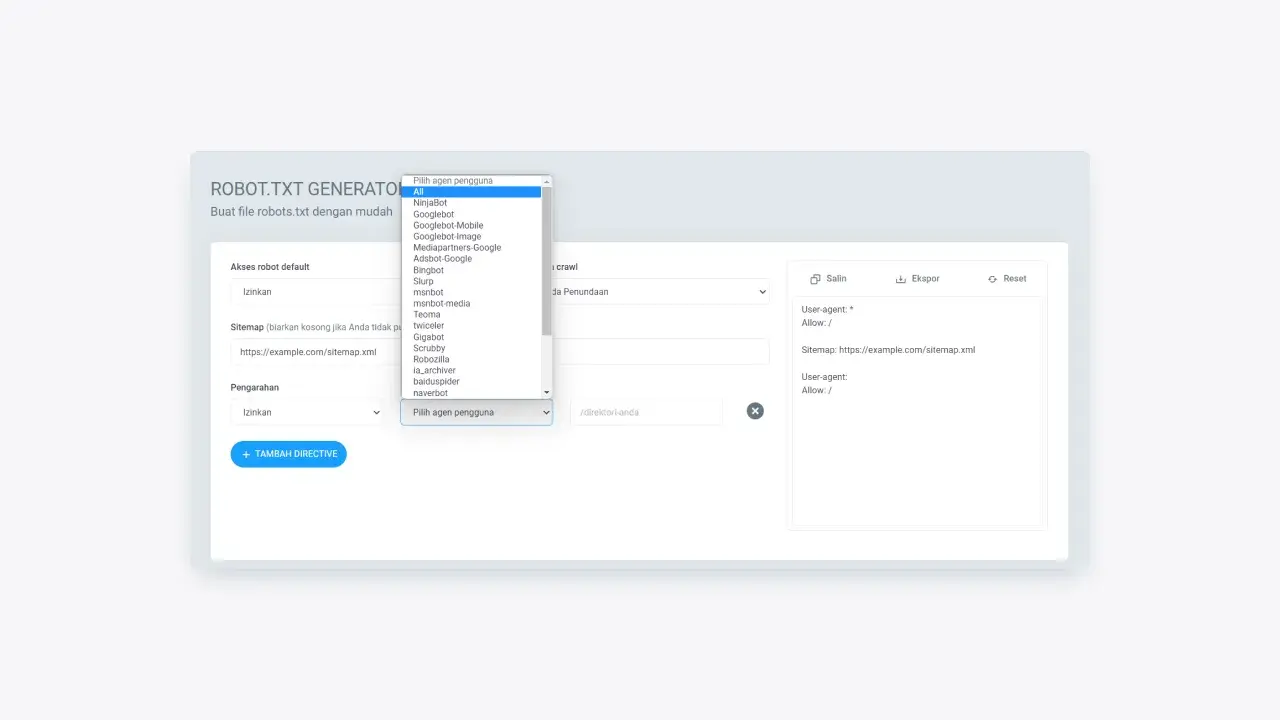
Figure 7: User-agent options available in cmlabs robots.txt generator
A directory or file path is a specific location of a page that web crawlers may or may not crawl. You must pay close attention to writing the path because this command distinguishes between upper and lower case letters (eg "/File" and "/file" are considered different paths).
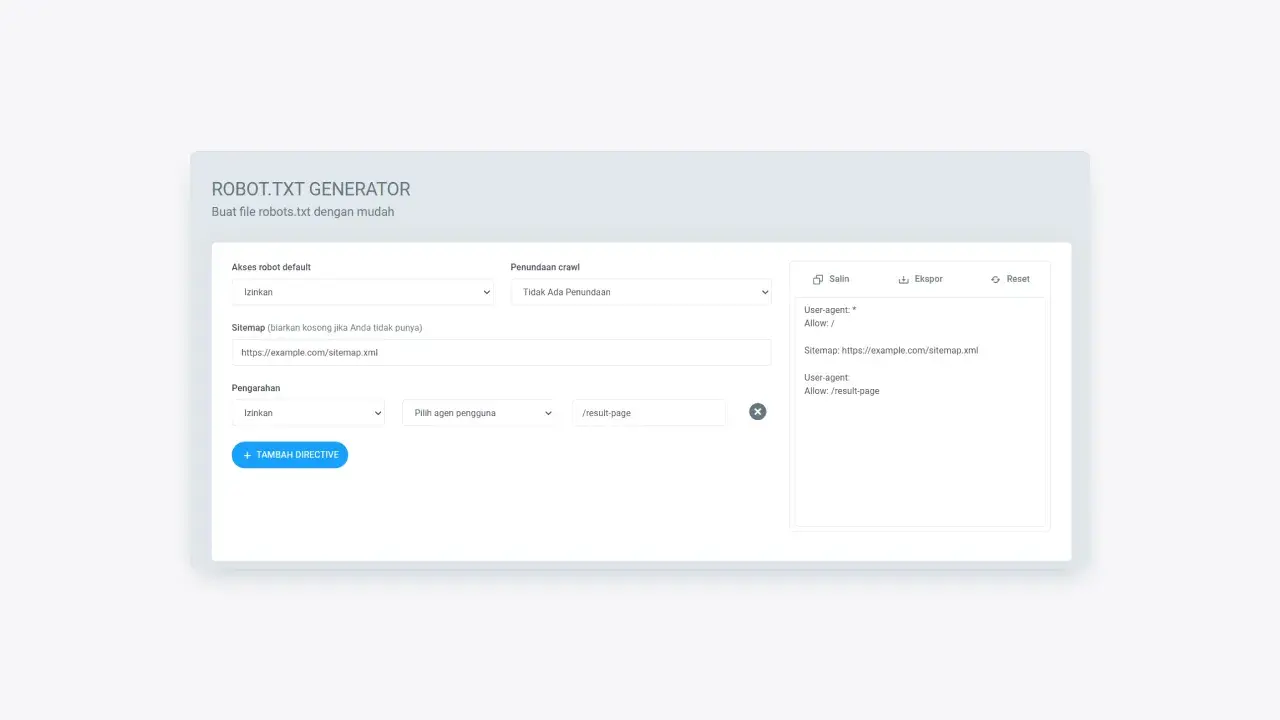
Figure 8: Field to add the path to be crawled by the crawler
After entering the command for the web crawler in the field provided, you will see a preview of the robots.txt file in the right section. You can copy the generated syntax and paste it into the robots.txt file that you have created.
Figure 9: Syntax copy options in the robots.txt generator.
If you don't know how to create your own robots.txt file, you can export the file that cmlabs has generated. Downloading the robots file is quite easy. You can select the "Export" option contained in the robots.text generator tools. Next, the tool will start the download and you will receive a robots.txt file.
Figure 10: Data export options in the robots.txt generator.
If you want to delete unneeded directives, then you can click the cross icon to the right of the field to enter the directive. Please note that deleted fields cannot be recovered.
Figure 11: The delete data directive option in the robots.txt generator
This tool has options that make it easier for you to find out how to create another robots.txt file. Click the "Reset" option to delete all the commands you set in robots.txt earlier. Next, you can create a new robots.txt configuration file.
Figure 12: Data reset options in the robots.txt generator.
Read More
Edited at Oct 13, 2023
The Search Engine Optimization (SEO) Starter Guide provides best practices to make it easier for search engines to crawl, index, and understand your content.

Jakarta, Indonesia (HQ)
cmlabs Jakarta HQ Jl. Pluit Kencana Raya No.63, Pluit, Penjaringan, Jakarta Utara, DKI Jakarta, 14450, Indonesia
(+62) 21-666-04470These strategic alliances allow us to offer our clients a wider range of SEO innovative solutions and exceptional service.
Psst! Hey there, SEO Stats and Tools SEO company! If you've ever planned of conquering the Indonesian market, you've come to the right place!

These strategic alliances allow us to offer our clients a wider range of SEO innovative solutions and exceptional service.
Psst! Hey there, SEO Stats and Tools SEO company! If you've ever planned of conquering the Indonesian market, you've come to the right place!


